

What's Ahead for Cross Tabs in 2025
Enough of diagnoses without treatments

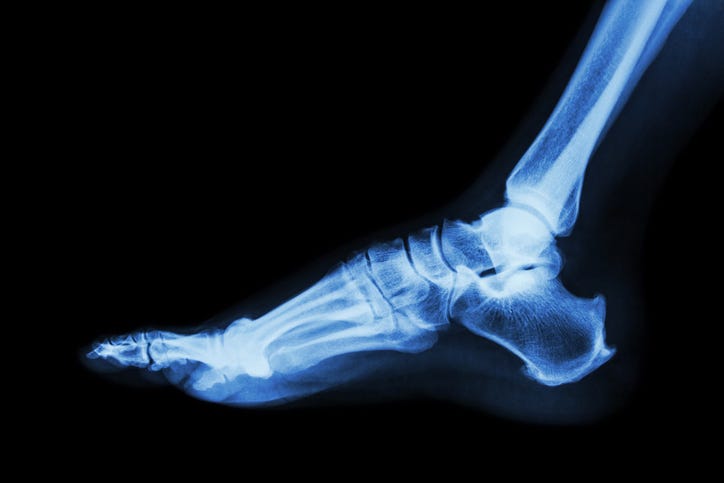
The Parable of the Big Toe
The other day I put on a nice new pair of Doc Marten’s and went into the city. By the time I got out of the train station and onto street level, I was limping. I limped into a restaurant, ordered breakfast, and paused to consider my predicament. I would be in the city all day. I did not have another pair of shoes. Even while sitting there with my coffee and eggs, the pain was mounting.
I limped down to my clinic and saw a doctor. The pain was in the big knuckle of my big toe, and so, she thought, it was probably gout. So she sent me for a blood test to confirm her diagnosis and then ordered an x-ray, mostly to appease me — because I told her the pain began after I lost my footing walking upstairs.
The blood work came back with no sign of gout; the x-ray came back with no sign of fracture. The doctor’s office sent me an email: great news! The bloodwork and x-ray came back clean and so there’s nothing wrong with your foot.
Ultimately what they told me was this: we measured the things we usually measure looking for things that are the most common causes of pain in this spot, and finding that those are not the causes of your pain, we conclude that there is nothing wrong.
Now, let’s say for the sake of argument that this is a form of diagnosis. It is a diagnosis that absolved them from providing treatment.
The Data Will Not Tell You What to Do
A thing clients of market research — and it seems of opinion research generally — often say is, “The data will tell us what to do.”
But this assumes that data is exogenous — that it simply exists.
This is the great lie about data.
Data does not exist.
Data is a recording we make when we measure something.
We decide what to measure.
We decide how to measure it.
We decide how to record it.
We decide whether to track it, compare it, or analyze it with math or theory or a combination of the two.
And then, once we’ve done that, we decide what to do about it.
(Or in the case of the data collected via bloodwork and an x-ray, we decide to do nothing.)
Another way for my doctors to have approached the diagnostic process would have been an open-ended approach. Rather than saying, “Let’s rule out a fracture and gout”, they could have said, “Let’s take as true that the pain began when the patient said it did, and try to figure out what happened. Let’s also just take a general history around her health, her foot, her overall joint health to see if this is part of a general trend.”

I used to say that a lot of people think about research, especially qualitative research, the way Dr. House, MD thought about his patients: “Everybody lies.”
But, assuming they really believe, that, they respond in a curious way. They don’t do what House did — try to figure out what’s really happening. Instead, they measure what they usually measure, take the responses with a grain of salt (because people lie and also statistics), and then they move on to the next question, the next sample, the next study.
The irony of data collection is it often leads us to stop asking questions.
As I look at the practice of opinion research, there is a lot of room for improvement in the decisions we make about whether to measure something, when to measure it, how to measure it, how to record those measurements, and how to make sense of those measurements. The way we do things now too often leads to two distinct forms of failure:
We mistake the acts of measuring and interpretation for “doing something”. So we in effect do nothing at all.
We take for granted the “most common” causes of behavior as being the “most likely” causes. This leads us to take the wrong action.
It seems that a lot of media, pundits, and consultants conclude that when they lose a campaign, fail to predict an outcome, or just don’t achieve their goal, that the best thing to do is go back and take more careful measurements.
But if they continue to measure the same things they’ve always measured, and continue to mistake measurements with diagnoses, and diagnoses with treatment, then they will continue to, in boxing parlance, lose.
The point is to win.
I was at a conference once with someone who’d worked on the Obama ‘08 campaign. He asked those in attendance what they thought a campaign is for. Earnest people offered all sorts of answers, “to represent a base of voters” or “to offer a slate of policies” or “to present a vision for the country”. I said, “to win elections.” Turns out, that was the answer he was looking for.
The same can be said of any data collection program — the point is to make the campaign (the marketing program, product launch, program implementation, investment of money/effort) successful. We measure things to tell if we’re succeeding, to look for reasons we’re not succeeding, and to look for opportunities to succeed more or faster.
Political polls — and especially public opinion polling — very often leave out the recommendations section. What should public officials, candidates, and campaigns do if they want to improve the metrics? What should they do if they want to succeed?
What we’re doing in 2025
As we go forward with the show, we’re going to do two things, and we’re going to do them somewhat simultaneously.
We’re going to try to explain how we got here that avoids “just so” stories. By that I mean we’re going to talk about how and why we developed the tools we have for measuring the beliefs and behaviors of our fellow citizens, and the way these measurements are part of a feedback loop that not only measures sentiments and behaviors but also influences them, and influences politicians and policy makers and political commentators and reporters (which then in turn also influence citizens). We’re going to do some history and psychology and philosophy along the way. I can not promise there will be no math.
We’re going to share solutions and strategies for improving the situation. “The situation” here refers to everything from how we measure public opinion, to what pro-democracy forces should do differently in the days and years ahead. It’s also about accountability — as others have noted, we’re in a “Murder on the Orient Express” situation: everybody did it. But “everybody did it” doesn’t mean “nobody did it.” So we’re going to call out institutions and organizations and individuals who are, let’s say, not part of the solution (even if they have no idea they’re part of the problem).
NB: This is not a viewpoint-neutral show.
I want to be clear about something else. This is not a politically agnostic show or newsletter. I have a very strong preference for democracy, and not simply because it is, ideally, a fair system for deliberation and policy-making, but because, at its best, it is designed to recognize human dignity, safeguard liberty, and foster human flourishing.
I do not care that much about traditions, but I do care a lot about values. The values they were built to safeguard are what matters about institutions; the institutions themselves have proven themselves to be worthless if they can not safeguard those values.
I don’t think that feelings are always facts, and I don’t think that perceptions are reality — but I do think that feelings and perceptions matter. We have to deal with them because they are critical filters for how people understand reality.
I value ideas and methods that enable effective action — we need information and inquiry as part of our sense-making process, but the point is to create a shared reality from which we can make something together. Anything else is purely “academic.”
So, this kind of meta-exercise, of using research and data as a mechanism for perspective-taking, sense-making, and decision-making, and, for want of a better term, world-building, is what this newsletter/show is interested in.
We’re going to have a mix of essays, reported shows with multiple on-air sources, and interviews. We’ll tell the story the best we can, and we’ll experiment a little bit to figure out what the best ways are.
We’re going to publish updates on the show on LinkedIn and Bluesky. The show will stay in your audio feeds; episodes will also be available on YouTube shortly after they go live in your feed.
A note about social media: we’re not going to be very active on Bluesky. We won’t be on X and we won’t be on Meta services. (We’d love to hear your comments, questions and feedback in the comments here, and on LinkedIn, though.) We just don’t think these are effective places to build community or share ideas, anymore.
So that’s what we’re up to.
Welcome to Season 2
This week, the first episode of Season 2 will begin. We’re starting with a discussion about nostalgia.
The word nostalgia comes from nostos + algos — or the suffering caused by the desire to go home again. It was coined to describe the sense of longing soldiers stationed far from home felt in war. It’s funny to think about starting from a place of yearning and suffering, of being ripped from the comfort and stability of home to be in a foreign land under conditions of conflict — but to be real, that’s where we are. Nostalgia is, as we have seen, political.
So I went to an authority on the matter, the theorist Grafton Tanner, author of The Hours Have Lost Their Clock: The Politics of Nostalgia and Foreverism. It’ll come out on Wednesday.
We’re also going to put a fun episode related to the topic from my other show “In the Demo” in the feed for you this week. It’s more fun than a lot of other things that’ll be in your feed, and that’s almost entirely because The Ringer’s Rob Harvilla is a terrific hang. You’ll get that in your feed on Wednesday, too.
If you read to the end, thanks. More to come, hopefully in smaller doses.